Using lakeFS with LanceDB¶
LanceDB is a vector database that allows you to store and query vector data.
LanceDB works directly on an object store, so you can use it to store and query vector data in lakeFS.
Configuring LanceDB to work with lakeFS¶
To configure LanceDB to work with lakeFS, configure it to use the lakeFS S3 Gateway:
import lancedb # pip install lancedb
db = lancedb.connect(
# structure: s3://<repository ID>/<branch>/<path>
uri="s3://example-repo/example-branch/path/to/lancedb",
storage_options={
# Your lakeFS S3 Gateway
"endpoint": "https://example.lakefs.io",
# Access key and secret of a lakeFS user with permissions
# to read and write data from that path
"access_key_id": "AKIAIOSFODNN7EXAMPLE",
"secret_access_key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
}
)
# table "vectors" on the branch "example-branch" in the repository "example-repo"
table = db.open_table('vectors')
# update and query some data!
table.add([{'id': '1', 'embedding': generate_embedding('some data')}])
df = db.open_table('vectors').search(generate_embedding('some other data')).limit(10).to_pandas()
Tip
For more information on configuring and using LanceDB, see the LanceDB documentation.
Use Cases¶
Running LanceDB on top of lakeFS has a few major benefits:
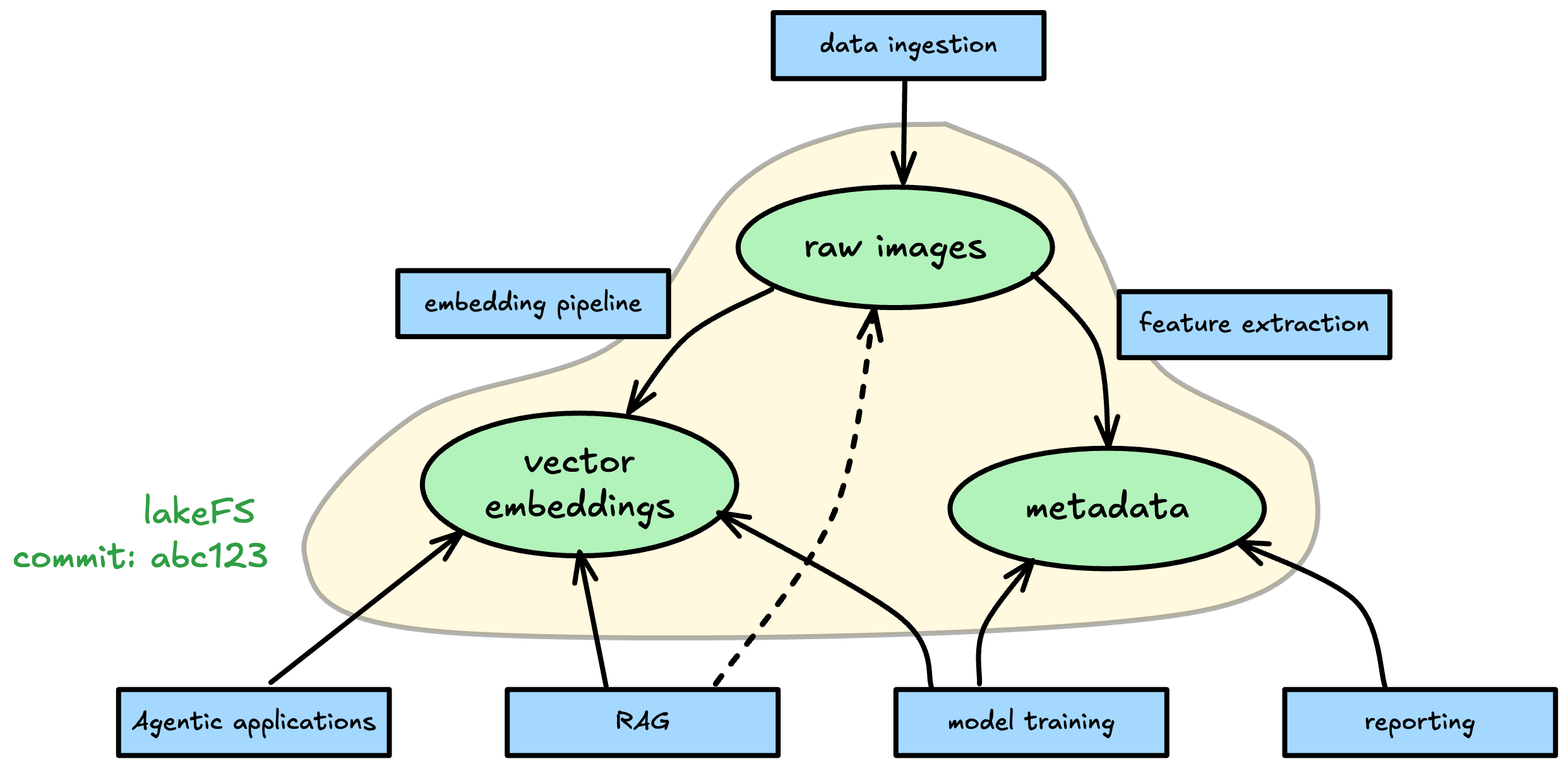
Multimodal data storage¶
In many cases, LanceDB stores embeddings of data that exists elsewhere: documents, images, text files etc. These "raw" data files are processed to extract embeddings, which are then stored in LanceDB - but they are also stored in their raw form for retrieval, and in some cases metadata about them is stored in other formats for use in a data warehouse or data lake.
By co-locating these embeddings together with the other modalities, you can perform more complex queries and analysis without giving up on consistency: a commit will capture both the vector embeddings, raw data, and metadata as one atomic unit.
Differential processing of new data¶
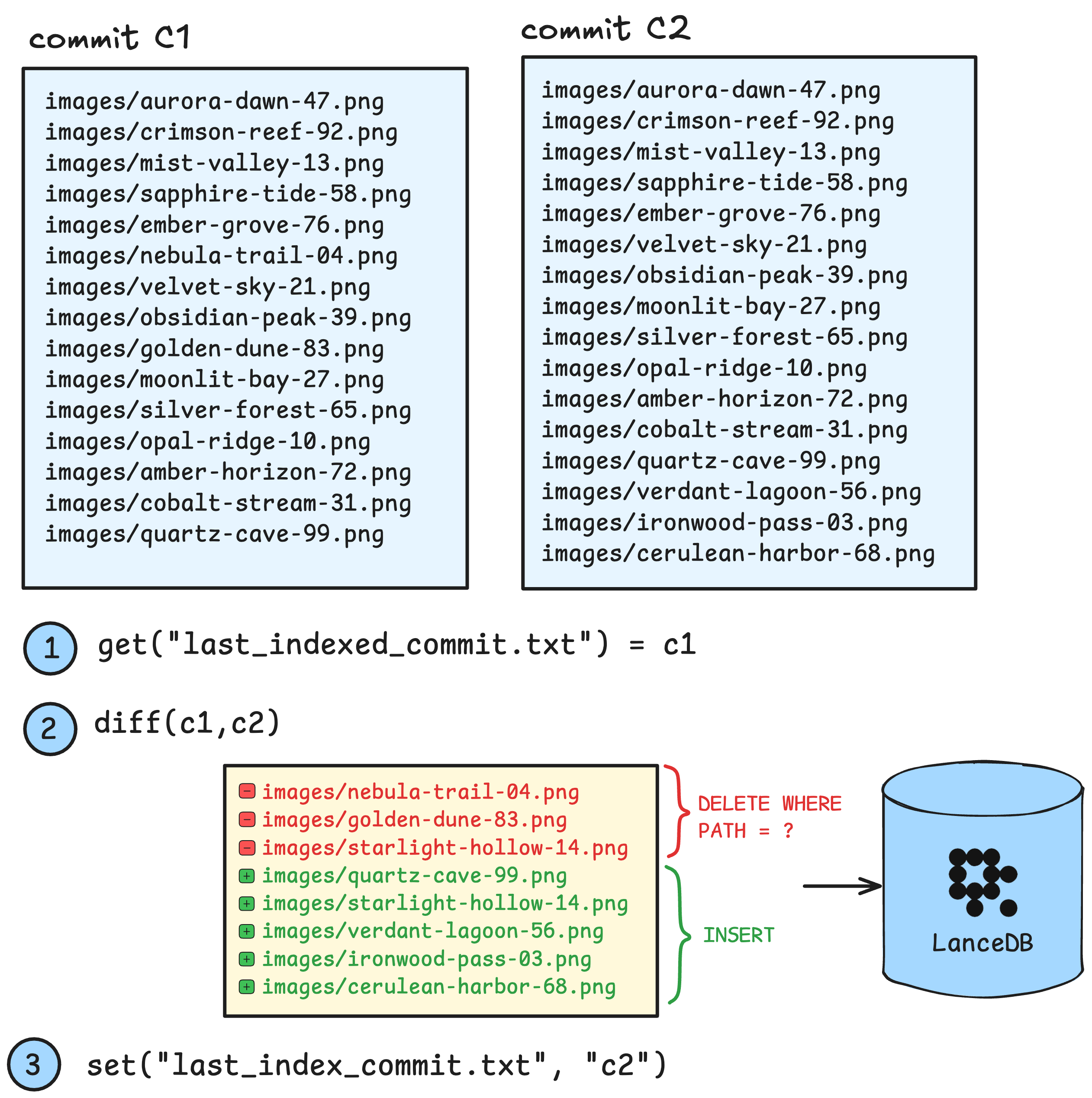
lakeFS provides a highly performant and scalable way understand how data changes over time. For example, say we store raw image data in images/ - we can update the raw data by adding, removing or updating images in the images/ directory - and lakeFS will capture the changes as a commit.
This allows you to perform differential processing of new data: If we have an images table in LanceDB we can keep track of the latest commit represented in that table. As new data arrives, we can update our embeddings with the latest commit by diffing the previous commit and the new one, resulting in a minimal set of embeddings to add, remove or update:
Ensuring high quality data with Write, Audit, Publish hooks¶
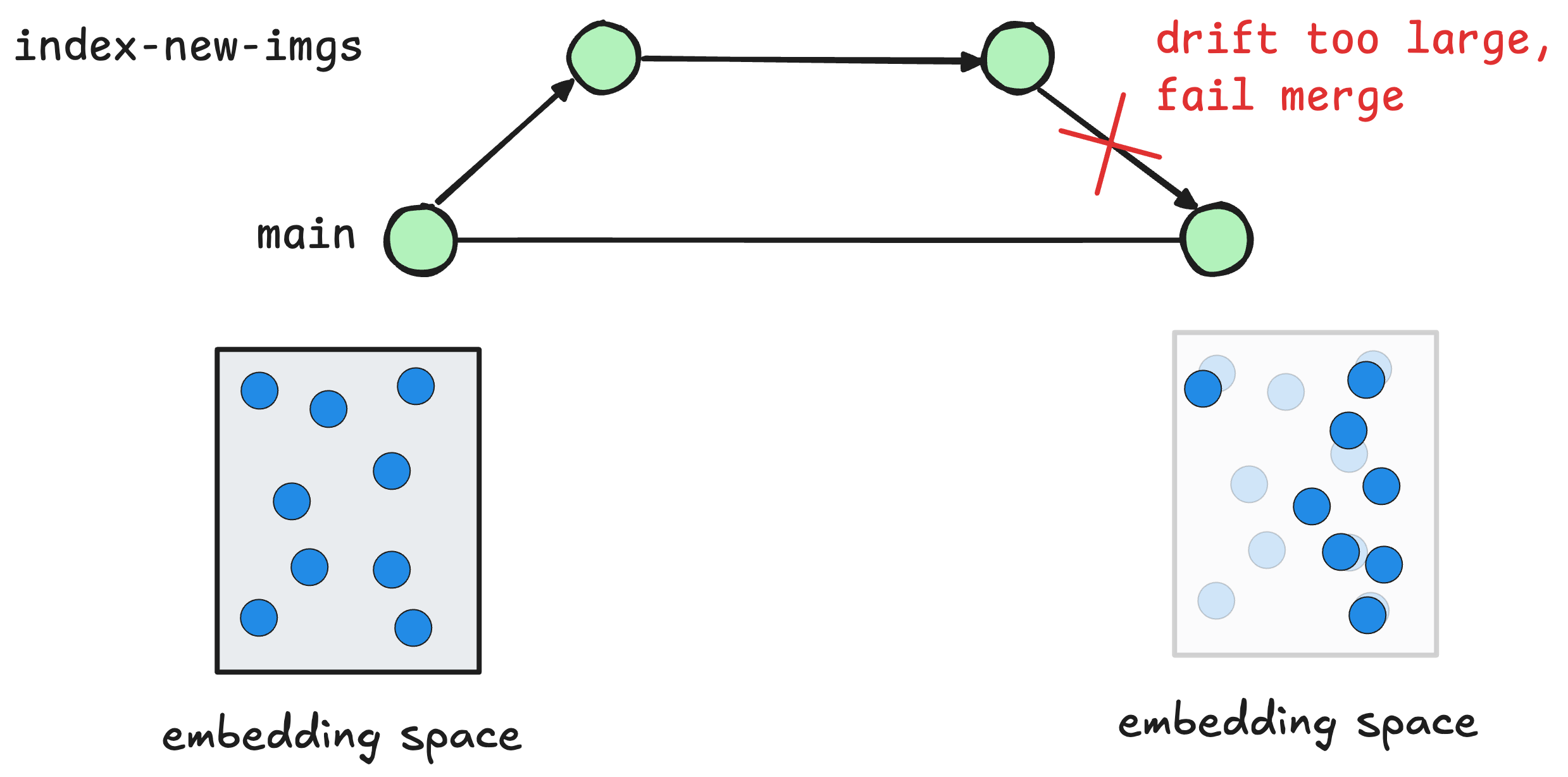
Using lakeFS hooks, you can ensure the vector embeddings meet a certain threshold for quality before they are made available for inference. These quality checks can be triggered automatically before new data is merged into a main or production branch. These tests could be:
- Coverage: How many of the images in the dataset have been processed and have embeddings? How many embeddings point to images no longer in the dataset?
- Governance: Are the embeddings consistent with the data policy? Do they contain any PII?
- Accuracy: Are the embeddings accurate? Do they match the expected output?
- Drift: Are metrics like centroid shift and norm drift within acceptable limits?
If any of these tests fail, the commit will be rejected and the data will not be made available for inference. This ensures that the data is of high quality and that it is consistent with the data policy.
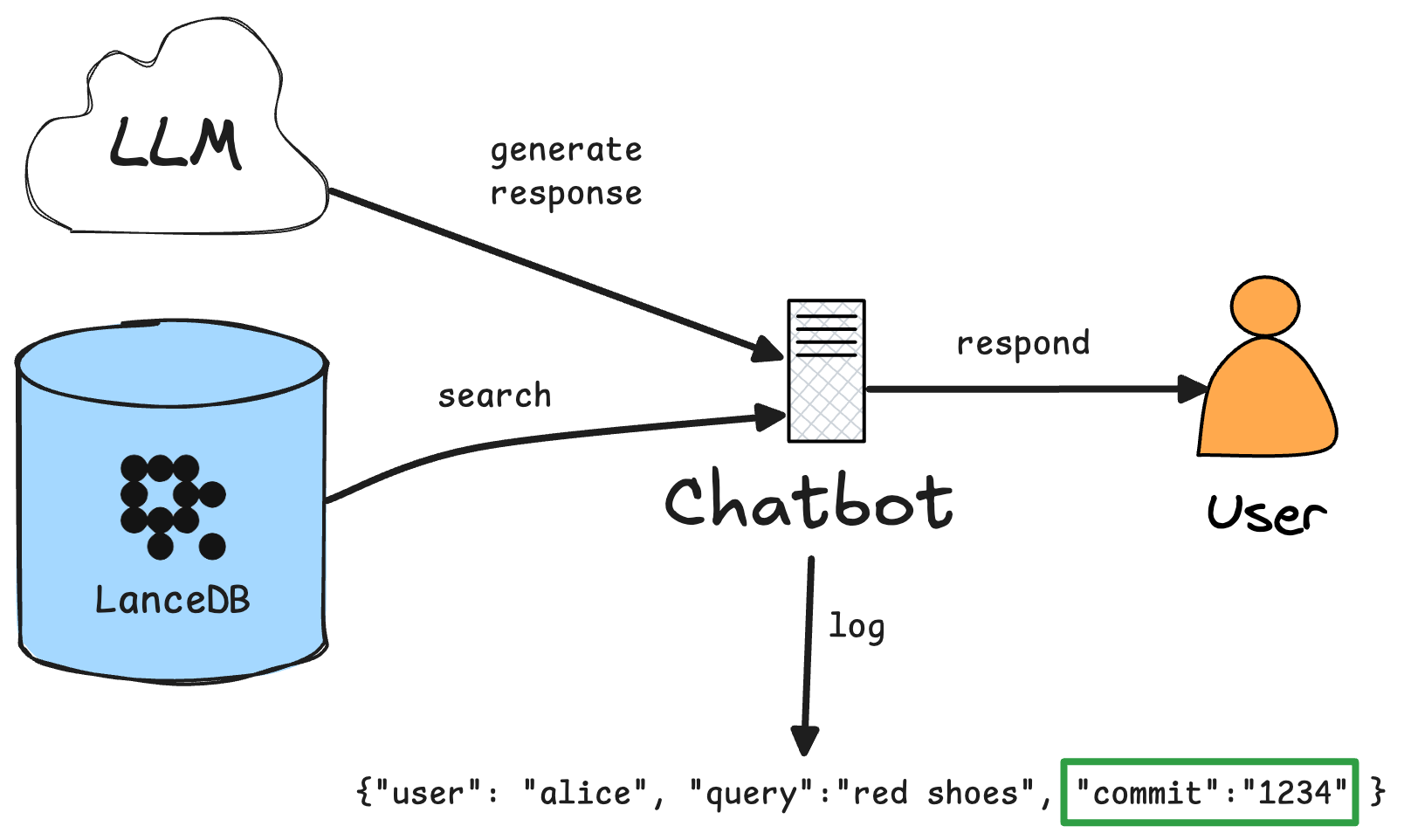
Traceable & Reproducible inference¶
Once deployed on lakeFS, querying the vector embeddings has to be done by specifying the branch, tag or commit ID of the data you want to query. Capturing the commit ID of the data you want to query allows you to reproduce the exact same results at any point in time. A common approach is to capture this commit ID in inference logs - allowing you to reproduce the exact same results as the user or agent that originally made the query.
While this sounds simple, vector databases often change quite frequently over time, making it hard to answer questions like "why did this customer complain about the chatbot being rude?" or "why did this product recommendation not work for this user?".
By tying that commit ID to the query, we can even go further and see the raw data as it existed at that point in time, complete with a commit log of who introduced that change, when and why.